San Cristóbal Acasaguastlán, en el departamento de El Progreso, concentra producción de maíz, frijol, tomate, chile pimiento, melón y sandía. Estos cultivos comparten un desafío estructural: alta sensibilidad a la variación de nutrientes en suelo y al timing de la lluvia, sobre una base productiva que históricamente dependió de estimación manual y datos mínimos.
El suelo del corredor San Cristóbal-Sanarate ha sido analizado. La mayoría de productores con acceso a extensión han recibido al menos un reporte de pH y NPK por ciclo. Los datos existen.
La desconexión que produce varianza "normal"
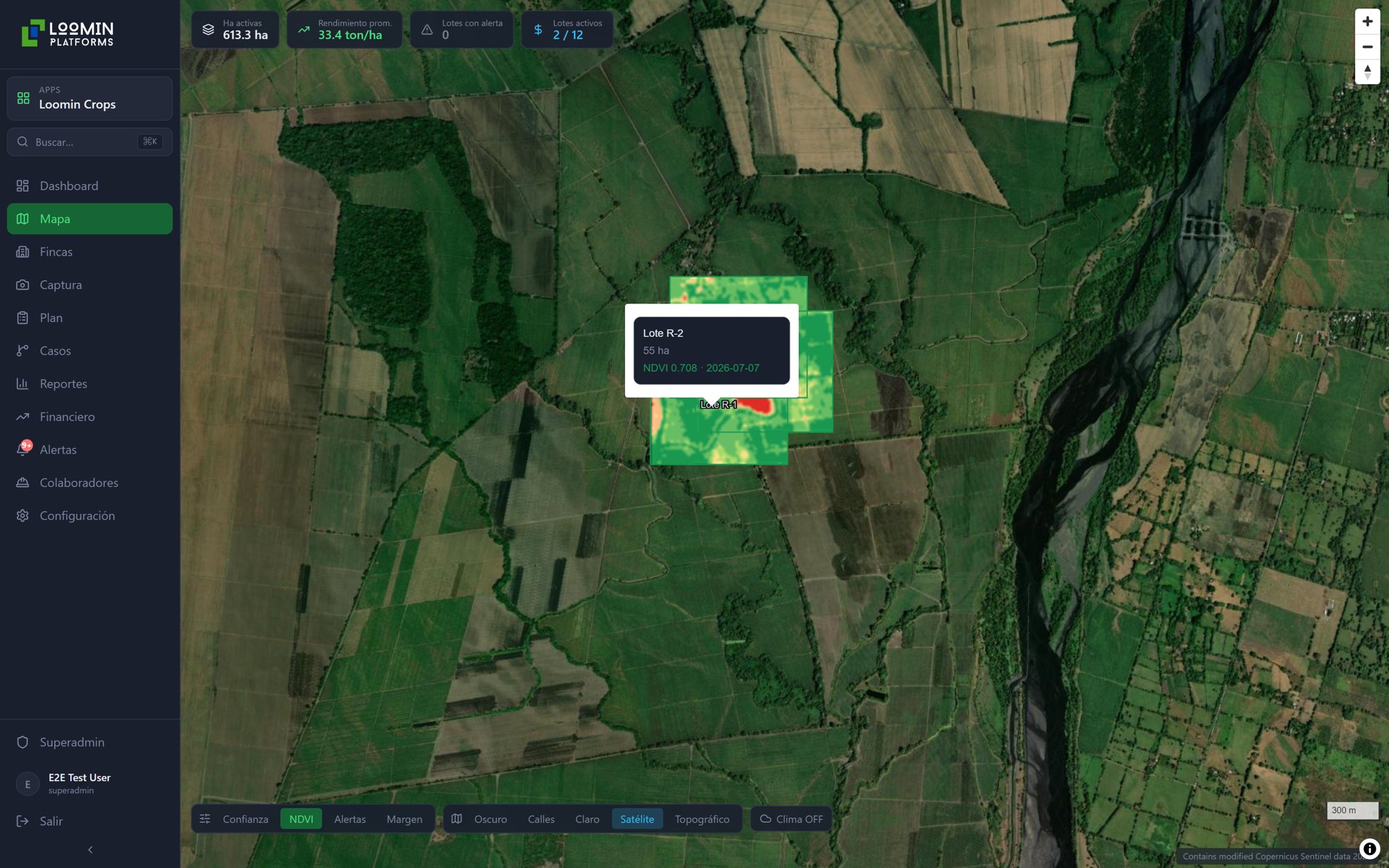
Lo que no existe es el sistema que cruza ese análisis de suelo con el registro de lluvia de esa ubicación específica, la variedad sembrada esa temporada y el historial de aplicaciones de los dos ciclos anteriores.
"Ese lote siempre rinde menos" es la explicación que se acepta. La explicación real es que nadie ha construido el modelo que diría por qué, y qué habría que cambiar para cerrar la brecha.
El resultado es una falla sistemática de predicción que no se percibe como falla: se acepta como varianza normal. Y esa varianza tiene un costo concreto en decisiones de insumo, en contratos firmados a volúmenes incorrectos y en logística planificada sobre números que no reflejan la realidad del campo.
El modelo que no requiere infraestructura nueva
La predicción por lote en este contexto no exige infraestructura costosa. Las imágenes de satélite (ESA Copernicus) cubren la región automáticamente cada 5 días a 10 metros de resolución. El registro de suelo ya existe en la mayoría de operaciones asistidas por extensión. El clima histórico localizado está disponible.
El eslabón faltante es la integración: el modelo que ingiere toda la información disponible y produce una predicción semanal, por lote, que acumula precisión con cada dato que llega. El Progreso no es un caso atípico. Es el caso representativo de la agricultura guatemalteca de escala media: rica en datos históricos, pobre en síntesis accionable.